1.现象

2.原因
集群资源使用率过高时可能会导致Hive On Spark查询失败-查询超时。
从hive on spark的架构看出超时的位置:
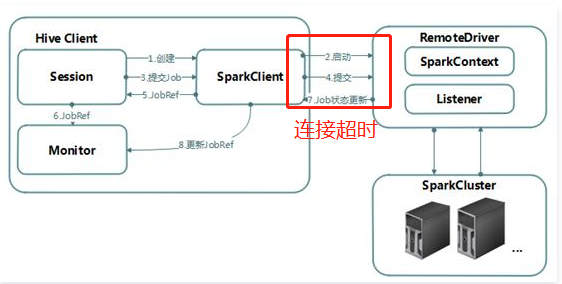
3.解决
修改以下参数,重启集群
### 其他可设置的参考参数
# 在Hive client和远程Spark driver通信过程中,随机生成密码的比特数。最好设置成8的倍数。
hive.spark.client.secret.bits
# 远程Spark drive用于处理RPC事件所用的最大线程数,默认是8。
hive.spark.client.rpc.threads
# Hive client和远程Spark driver通信最大的消息大小(单位:byte),默认是50MB。
hive.spark.client.rpc.max.size
# 远程Spark driver的通道日志级别,必须是DEBUG, ERROR, INFO, TRACE, WARN中的一个。
hive.spark.client.channel.log.level
# 用于身份验证的SASL机制的名称。
hive.spark.client.rpc.sasl.mechanisms
#生产集群设置的相应参数:
hive.spark.client.future.timeout=360s # Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。
hive.metastore.client.socket.timeout=360s # 客户端socket超时时间,默认20秒。
hive.spark.client.connect.timeout=360000ms # Spark driver连接Hive client的超时时间,如果没有指定时间单位,默认就是毫秒。
hive.spark.client.server.connect.timeout=360000ms # Hive client和远程Spark driver握手时的超时时间,这个会在两边都检查的,如果没有指定时间单位,默认就是毫秒。
hive.spark.job.monitor.timeout=180s # Job监控获取Spark作业状态的超时时间,如果没有指定时间单位,默认就是秒。