一、hive中文注释乱码
1、设置 hive 元数据库字符集
show create database hive;

查看为 utf8,需变更为 latin1
alter database hive character set latin1;

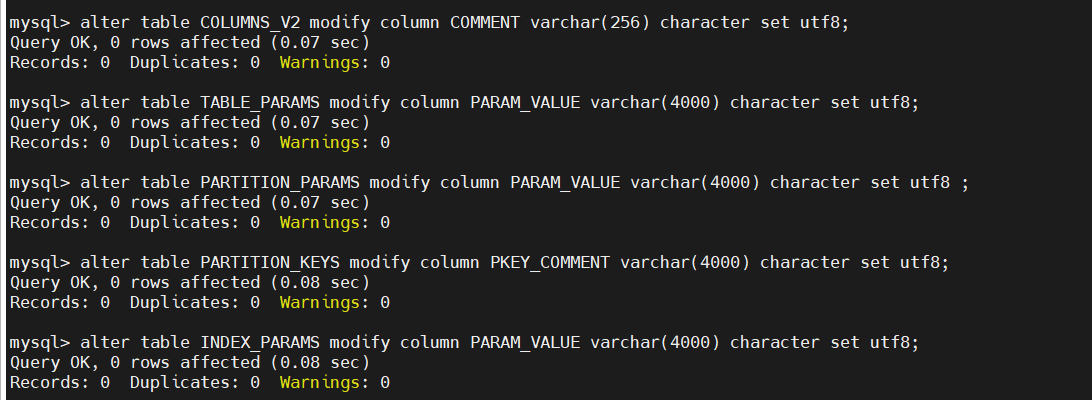
2、更改如下表字段为字符集编码为 utf8
①修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
② 修改分区字段注解:
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
③修改索引注解:
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
3. 验证
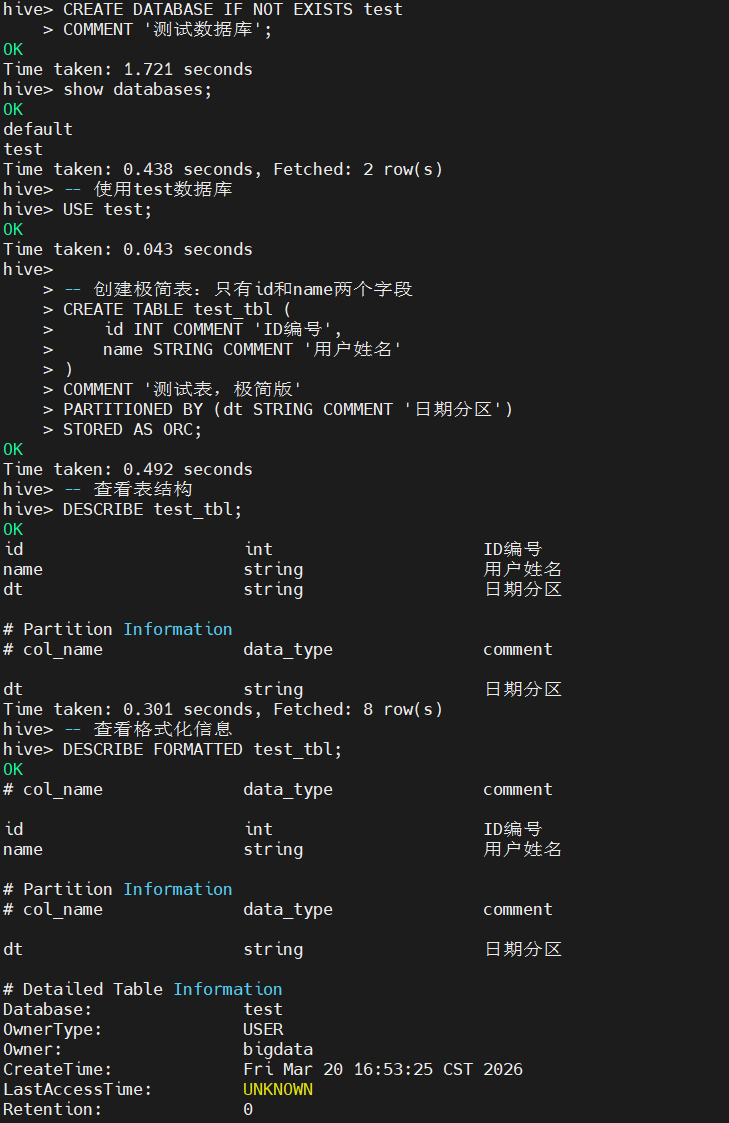
二、Impala时区和hive不一致
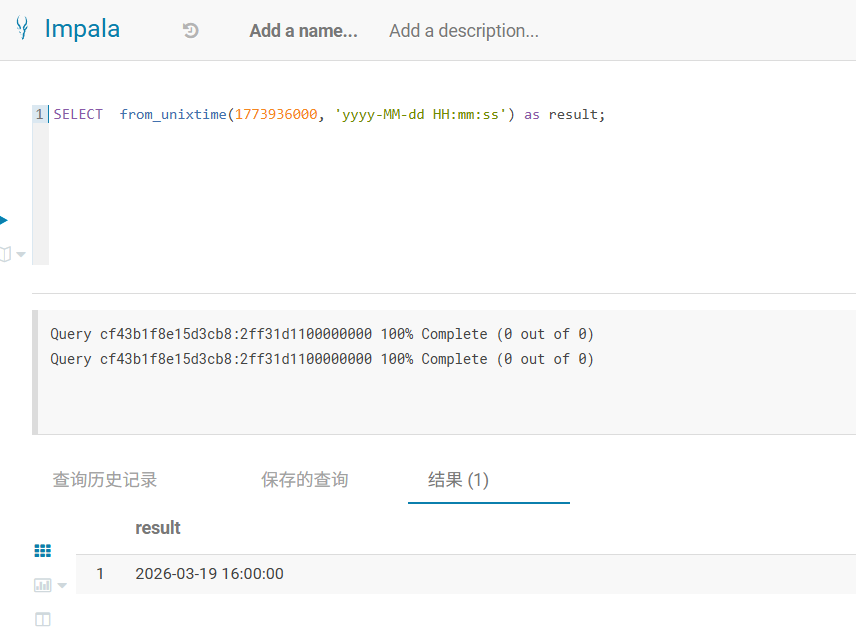
1.impala时间早8小时
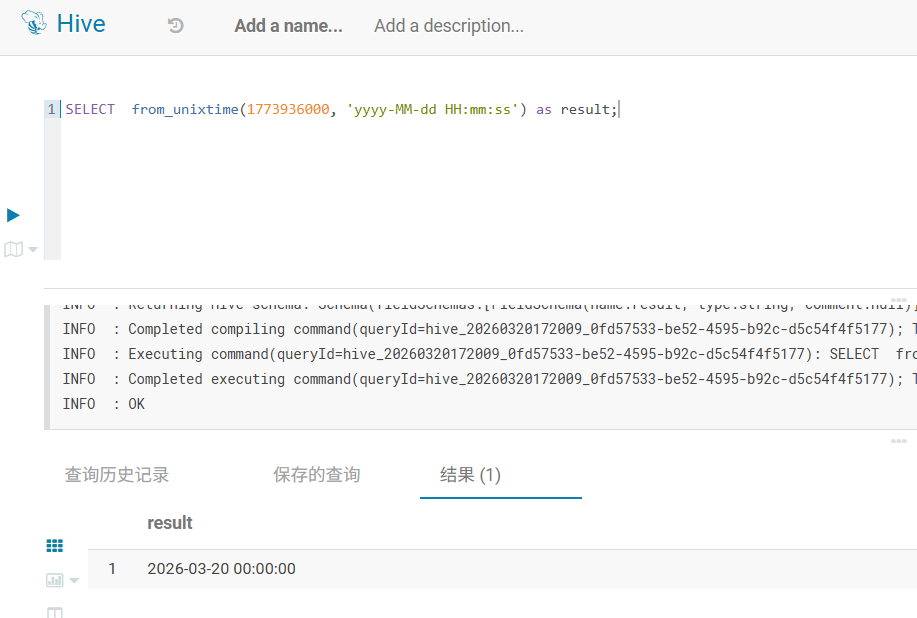
2.hive时间正常
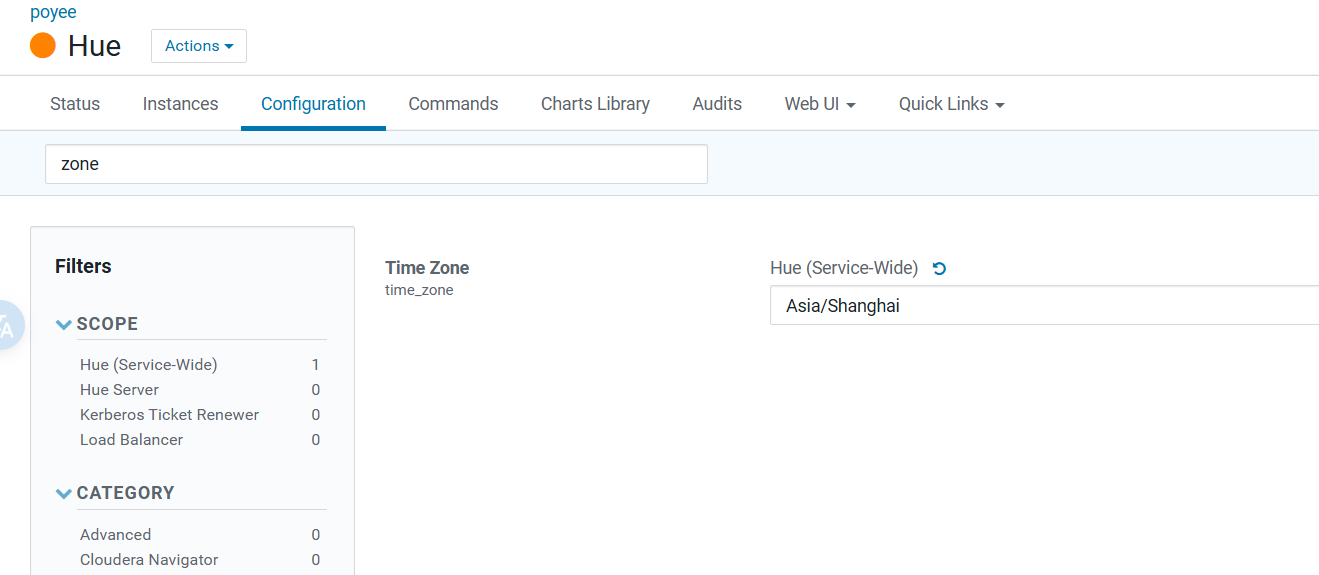
3.修改hue时区:
将America/Los_Angeles改为Asia/Shanghai
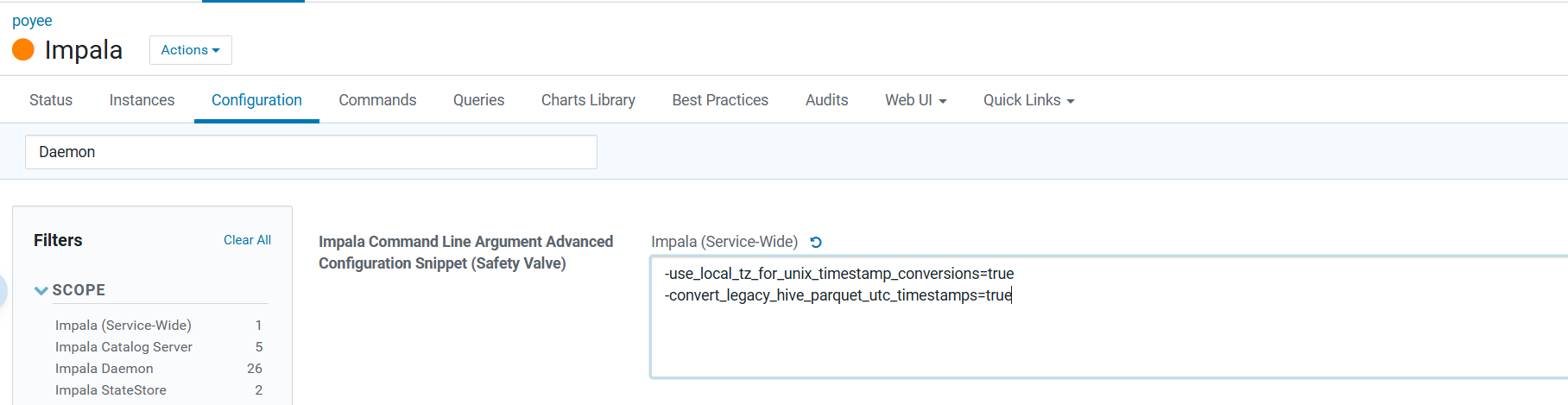
4.修改impala配置:
新增impala 命令行参数高级配置片段(安全阀):
-use_local_tz_for_unix_timestamp_conversions=true
-convert_legacy_hive_parquet_utc_timestamps=true
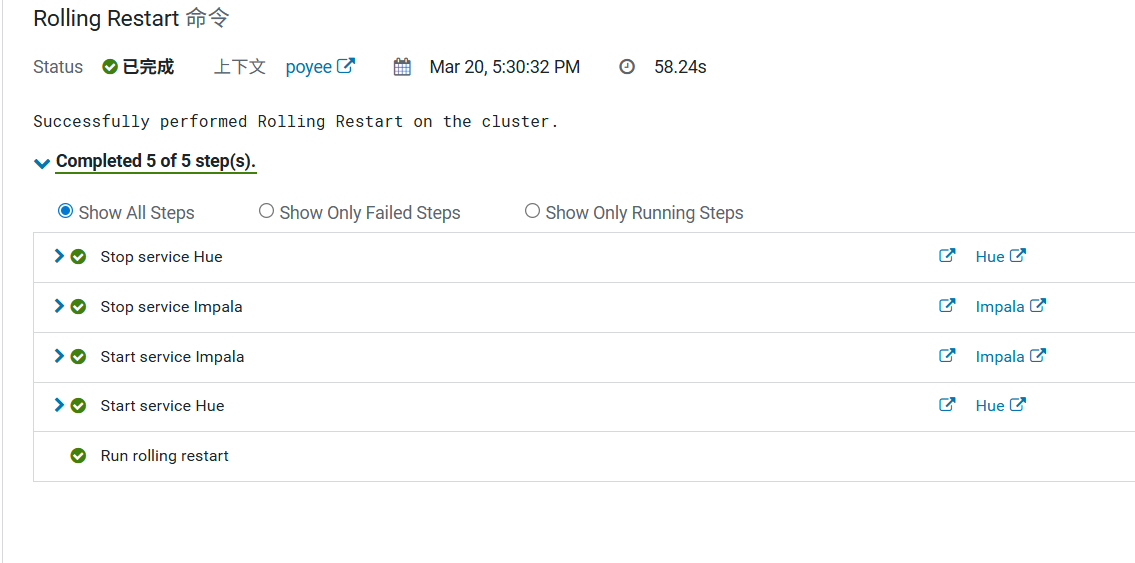
5.滚动重启
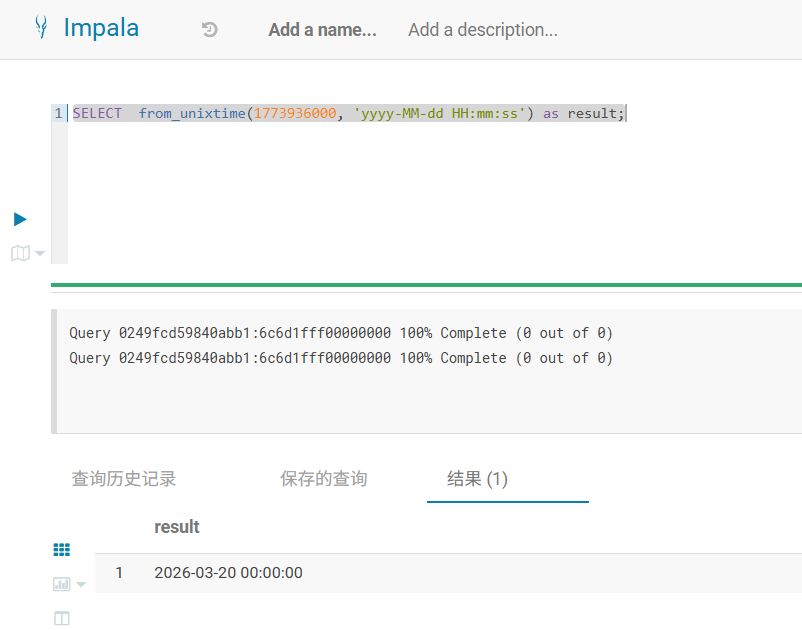
6.验证
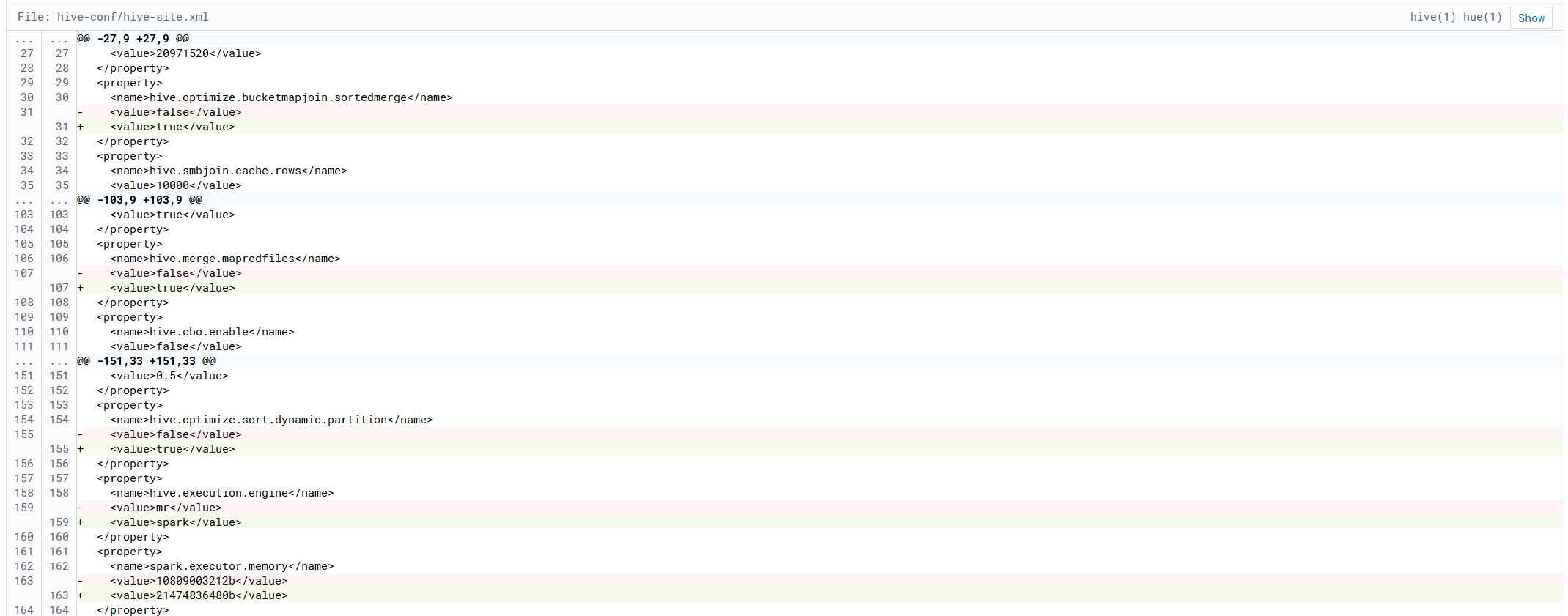
三、hive配置默认计算引擎为spark
1.原默认计算引擎

2.修改配置项,重启hive服务
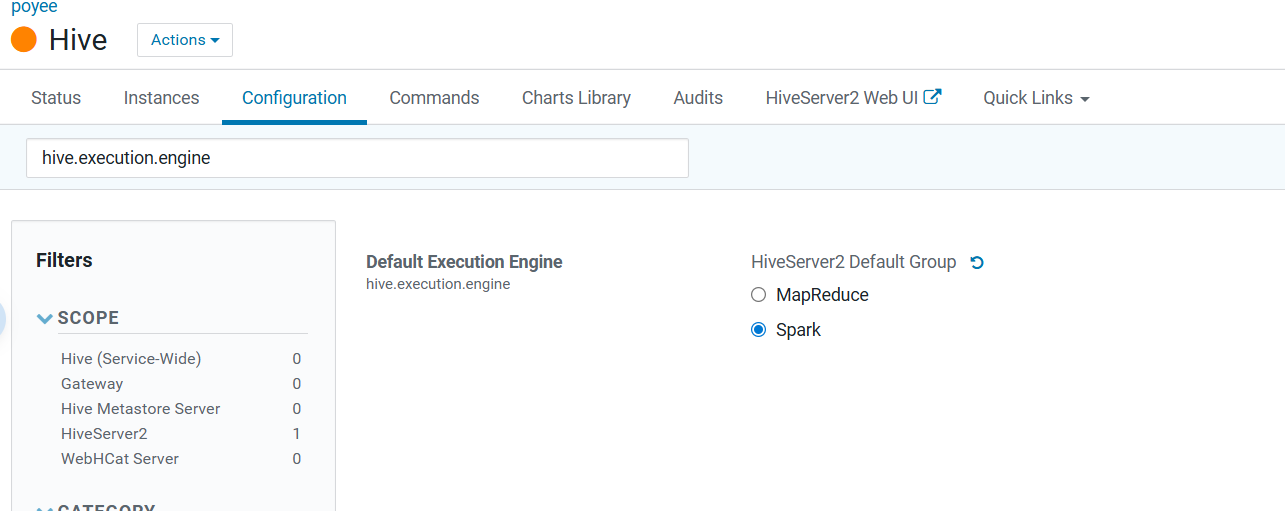
3.验证

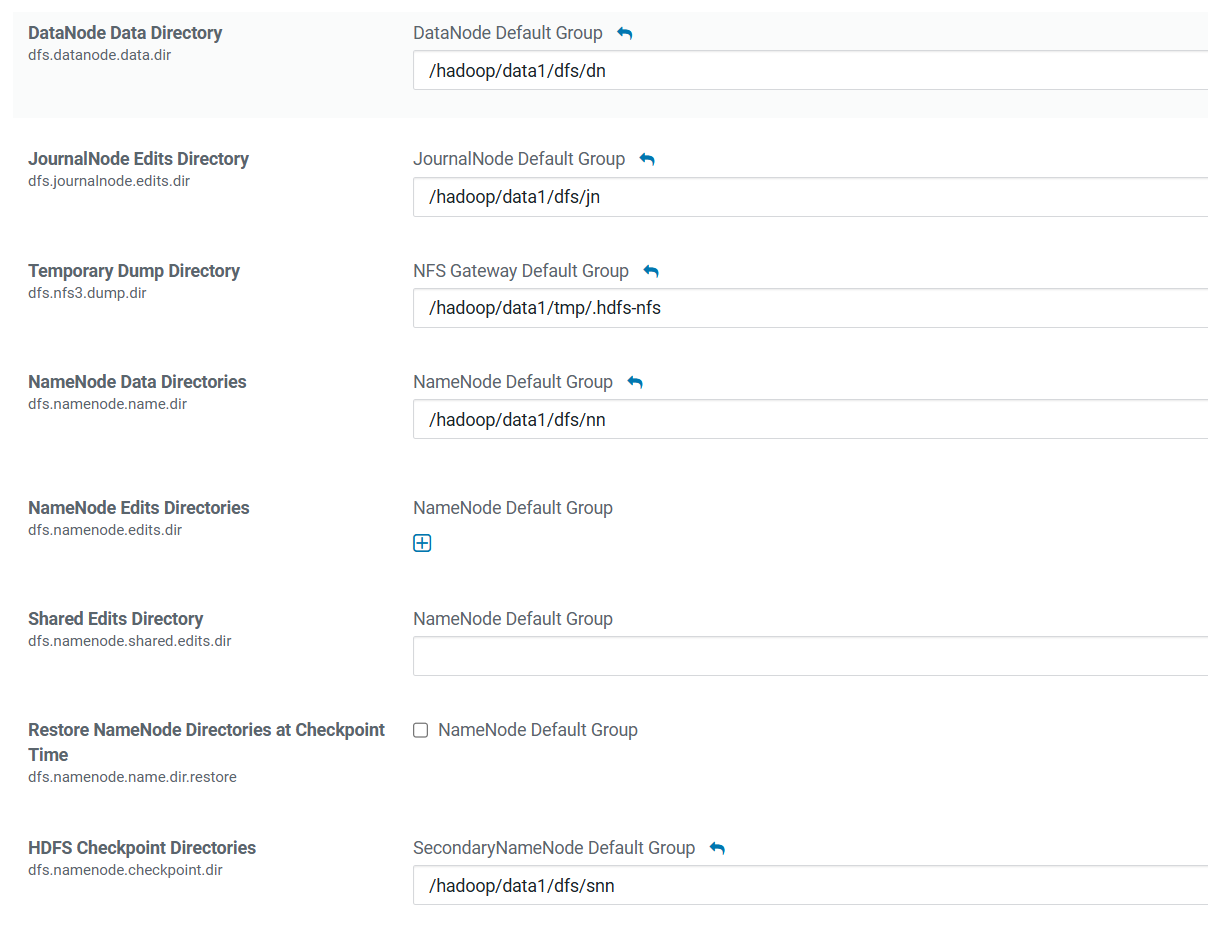
四、修改数据存储目录到新加数据盘挂载目录
1.hdfs:
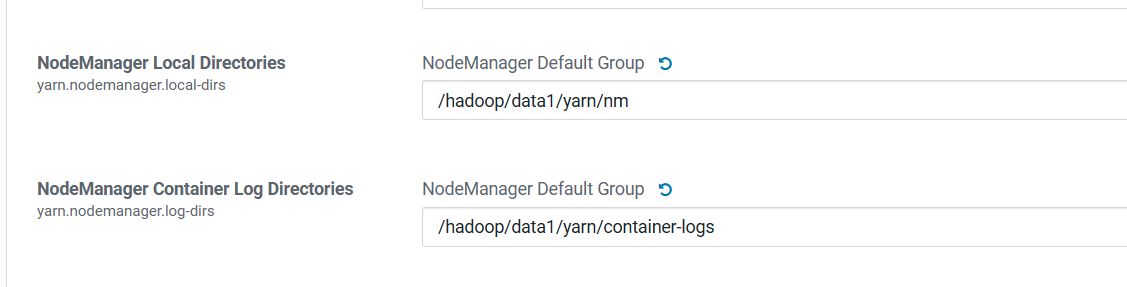
2.yarn
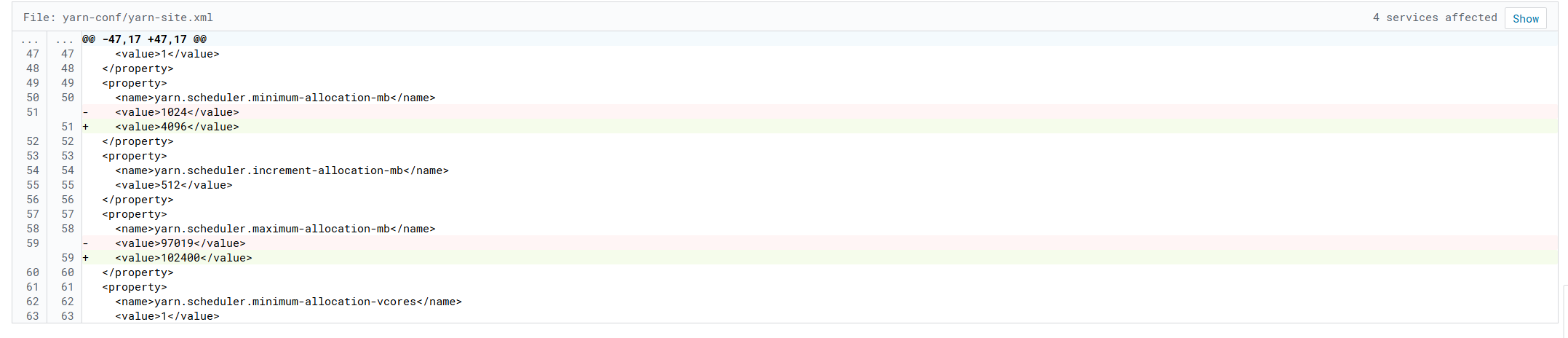
五、内存配额调优
-
每台机器可用内存:250G*0.8=200G(0.2预留系统和管理组件)
项 内存 描述 impala 30G 提供即席查询服务 yarn(spark) 150G 承担主要计算任务 冗余 20G 防止JVM 抖动、OOM等 -
暂时按220G可用来配,后面升级配置到250G版。220G×0.8=176G
| 项 | 内存 | 描述 |
|---|---|---|
| impala | 30G | 提供即席查询服务 |
| yarn(spark) | 126G | 承担主要计算任务 |
| 冗余 | 20G | 防止JVM 抖动、OOM等 |
3.后期:
worker节点内存均匀后,yarn(spark)配置:126G →150G
4.配置项
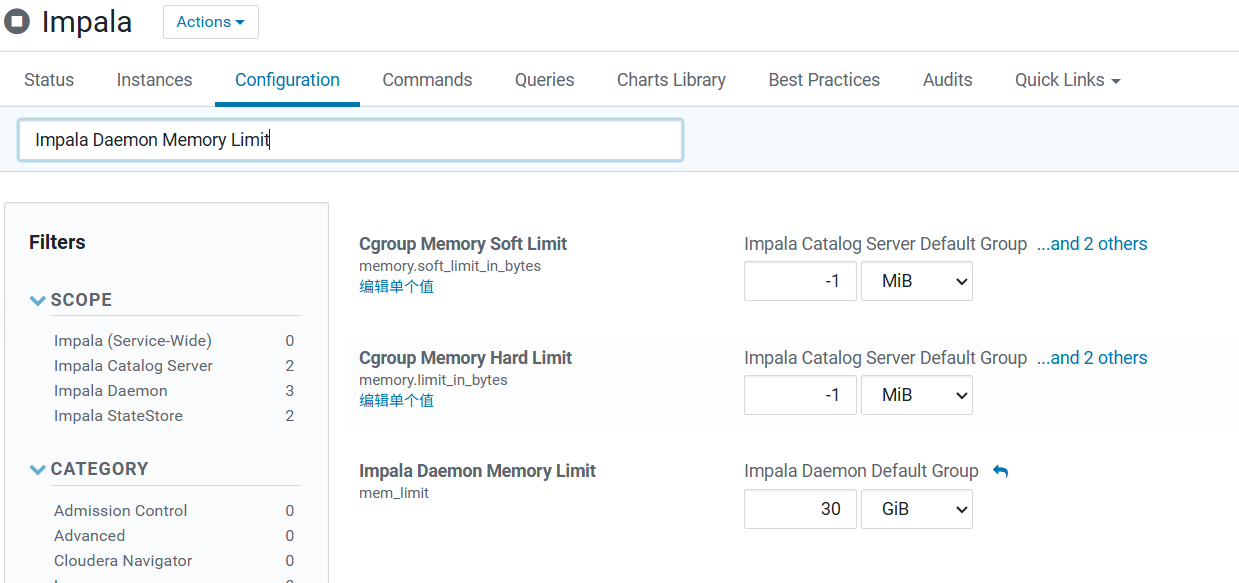
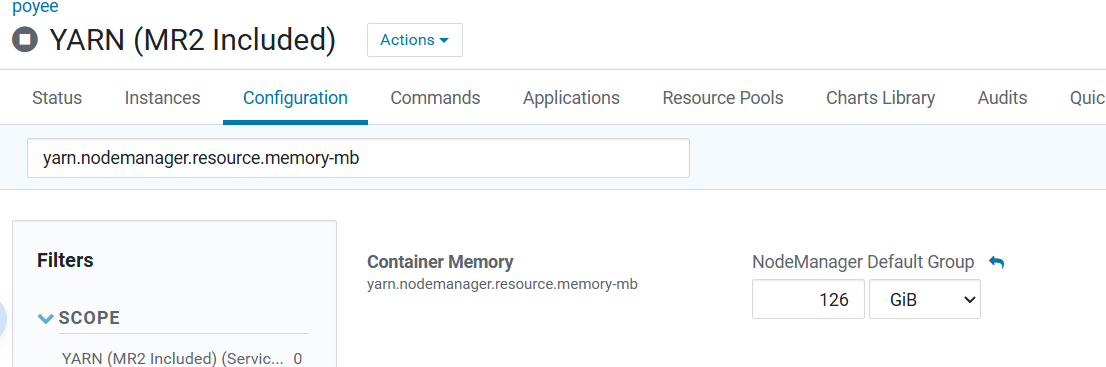
Impala Daemon Memory Limit
yarn.nodemanager.resource.memory-mb
六、hdfs
线程4096→65535

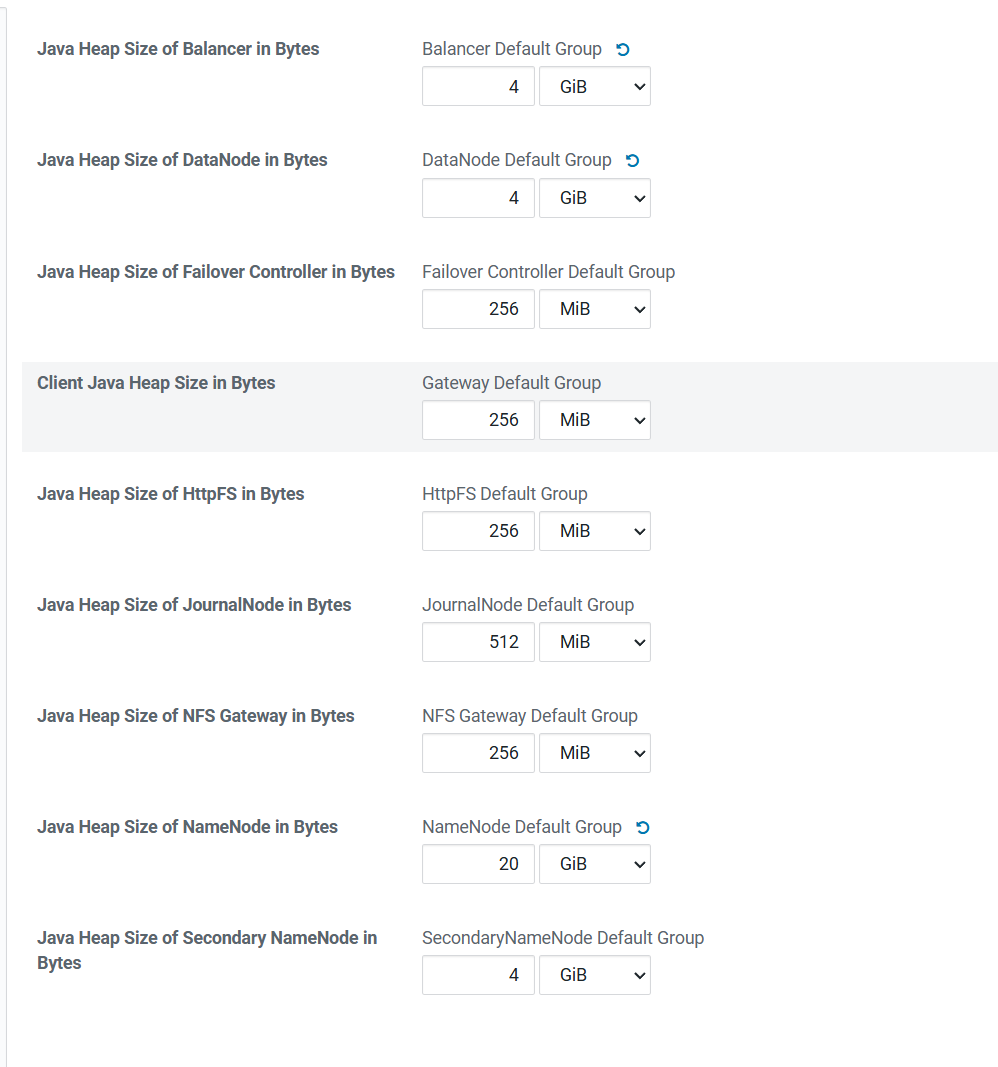
datanode和blancer堆内存1G→4G
namenode堆内存4G→20G
回收站清理 1day→14day

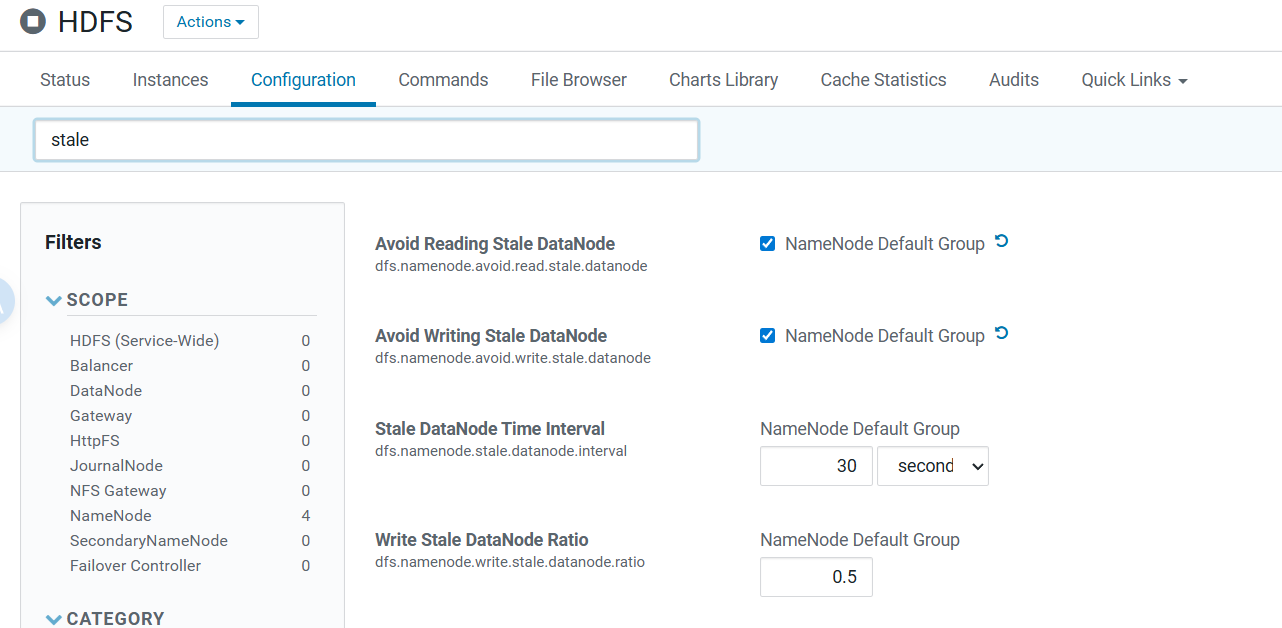
stale启用(避免脏读脏写)
七、hive
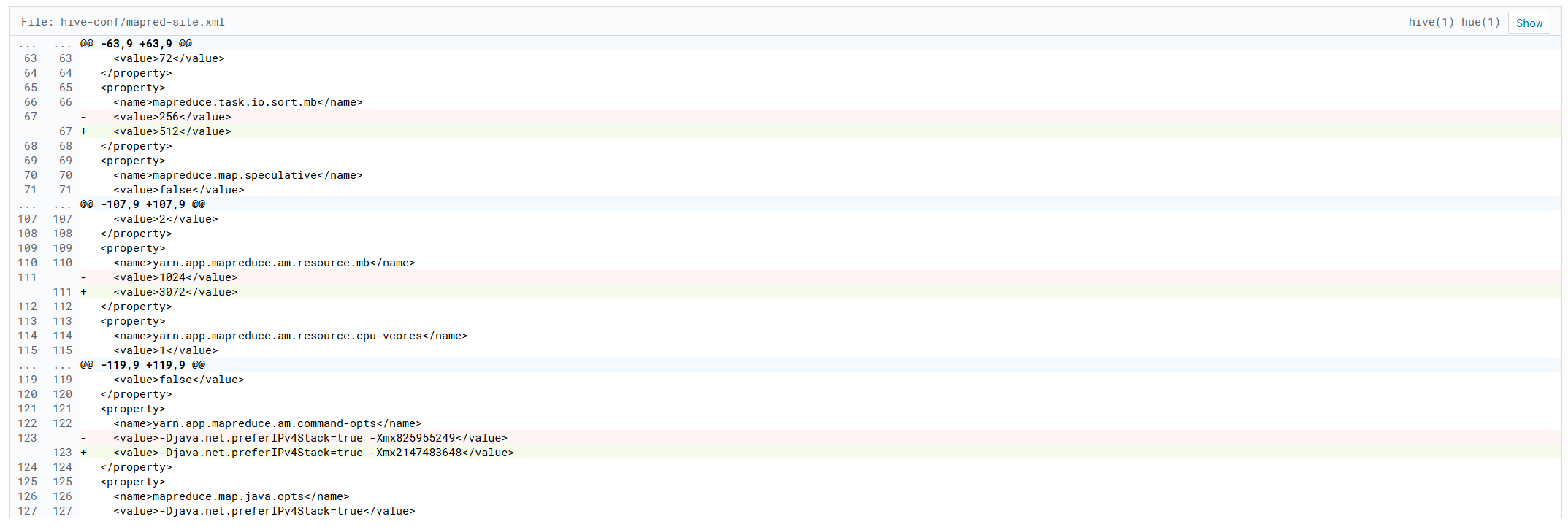
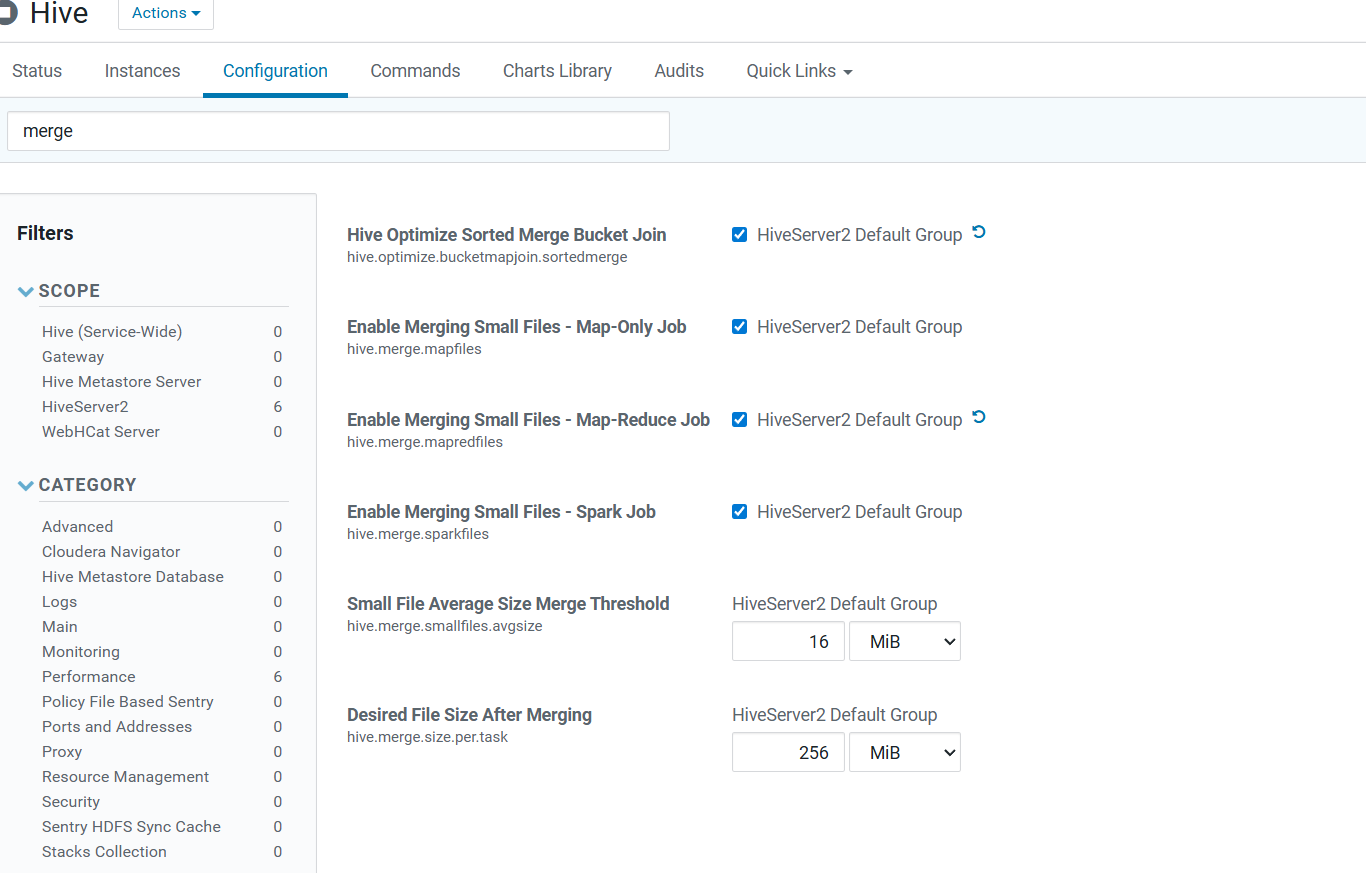
小文件合并
动态分区优化
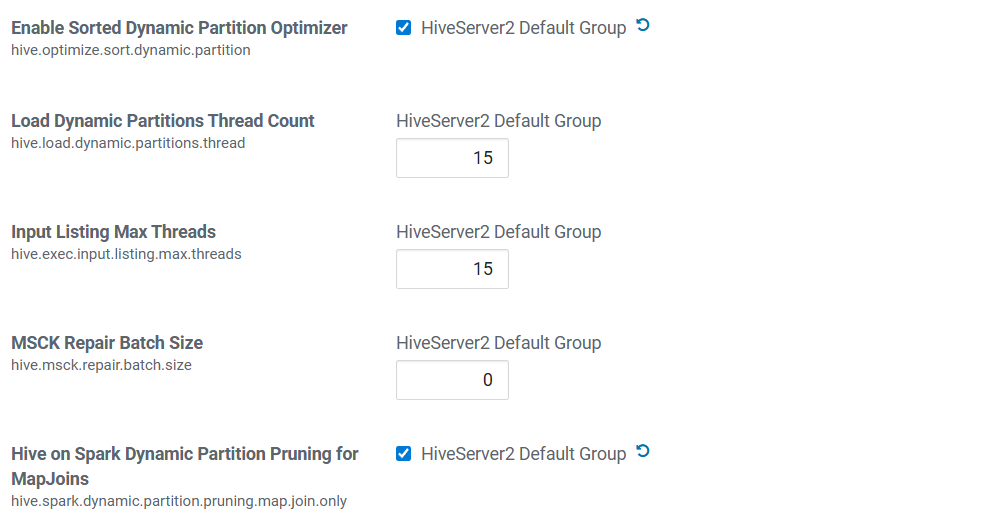
spark资源调优
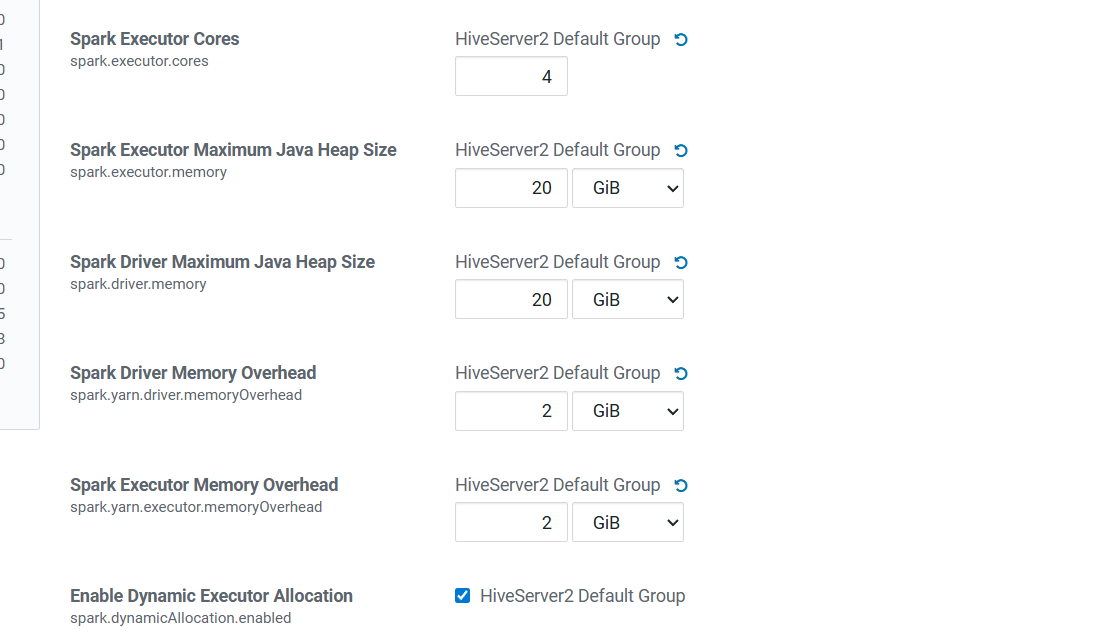
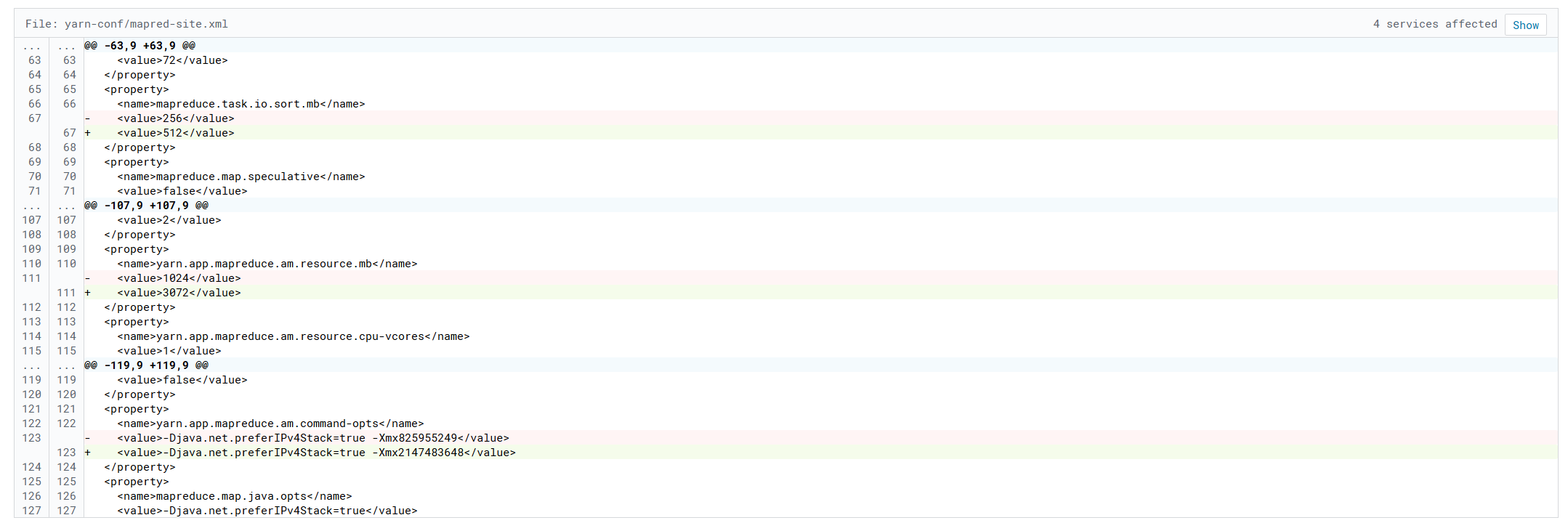
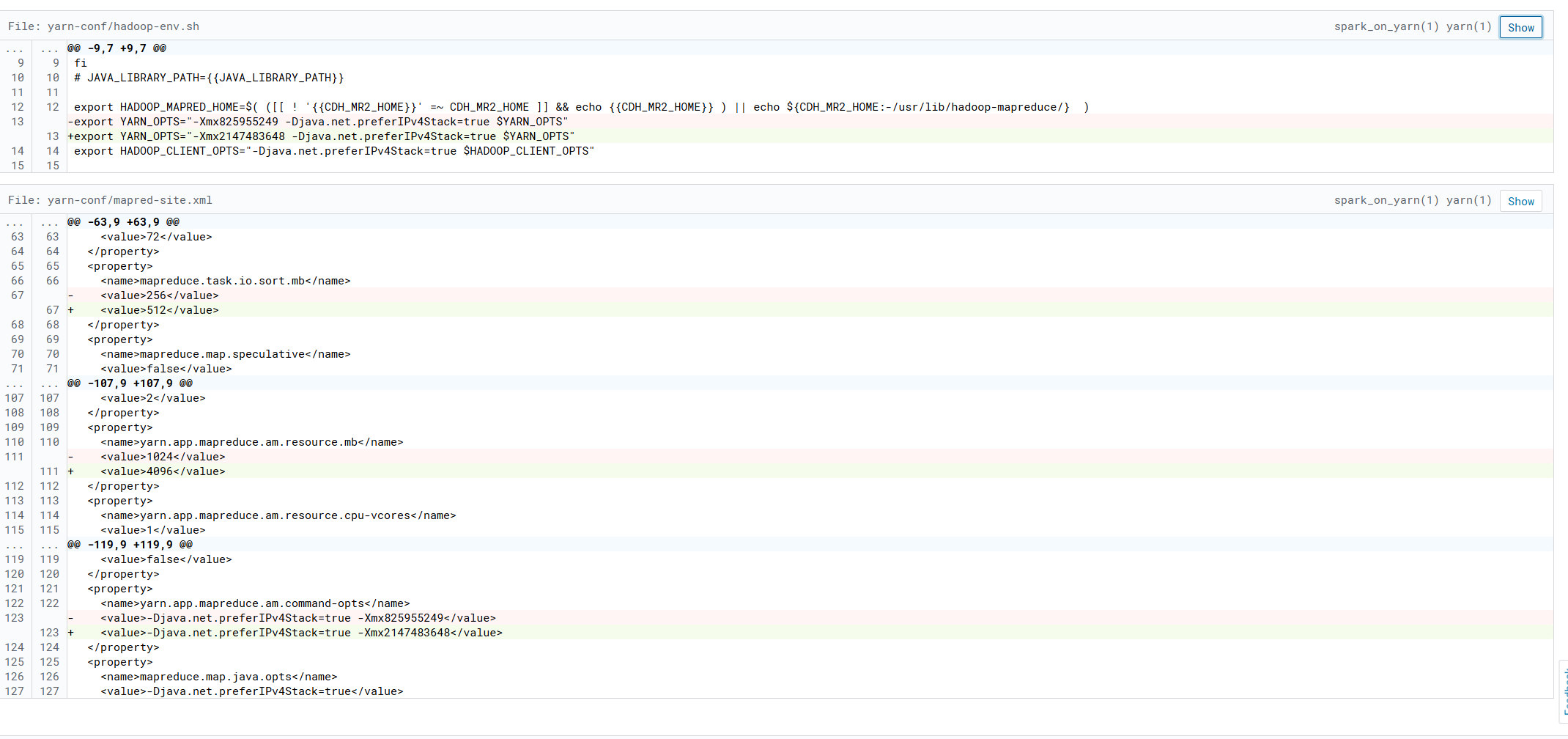
八、yarn
调整yarn内存,jvm内存
调整容器最大最小内存
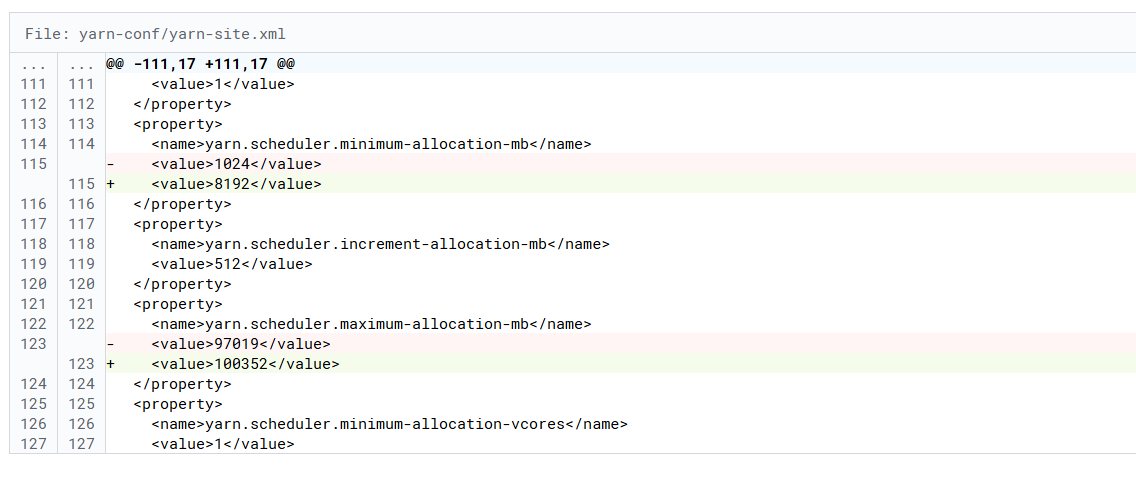
九、一些目录配置的更改:
-
hdfs上,一些目录的创建及赋权,如
hdfs dfs -mkdir -p /user/spark/applicationHistory hdfs dfs -chown -R spark:spark /user/spark/applicationHistory hdfs dfs -chmod -R 1777 /user/spark/applicationHistory -
cdh界面配置,将所有/var/log → /data/var/log , /tmp → /data/tmp
-
创建opt/cloudera/parcels软连接指向/data下
十、修改默认纠删码策略为无。(保证副本策略为3)
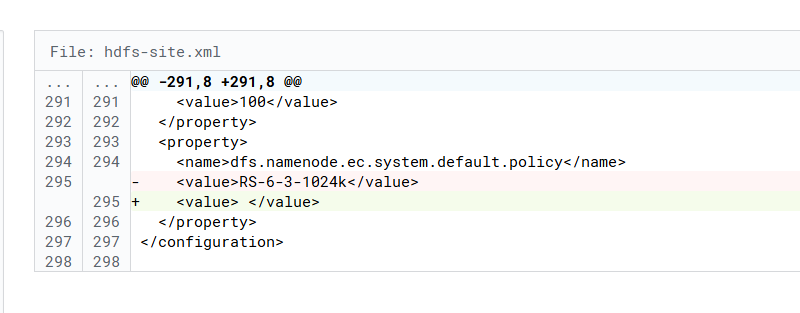
目前datanode节点太少,纠删码不起作用,后期扩展节点可作为冷数据压缩空间的优化项,膨胀率3→1.4。
十一、修改网卡检测项:
- 排除办公网vpn网卡检测

十二、系统的/var太小,导致警告
- 修改各组件的日志目录,/var/log → /data/var/log 。
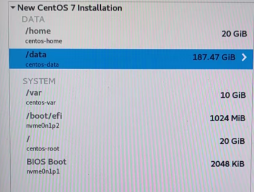
新配置:
/boot/efi 1G
/boot 1G
剩下的都给 / 230G
数据盘: /hadoop/data1
十三、 worker节点熵值不均
cdh报:Test of whether a host has enough entropy. Concerning : 72 entropy was available. Warning threshold: 100
什么是 entropy(熵)?
在 Linux 系统中,熵是用于生成随机数的“随机性来源”,主要用于:
SSL/TLS 加密(HTTPS、Kerberos)
SSH 连接
Hadoop / CDH 安全通信
如果熵太低,会导致:
加密操作变慢
某些服务启动卡住(尤其是涉及安全认证时)熵值不是“配置出来的”,而是“系统实时积累的随机性”
谁“更活跃/更有随机输入”,谁熵就高为什么必须统一?
否则会出现:
某些节点启动快(高熵)
某些节点卡住(低熵)
在 Hadoop 里可能导致:
Kerberos 卡死
HDFS 启动慢
Agent 心跳异常
解决:所有节点统一装 haveged
yum install -y haveged
systemctl enable haveged
systemctl start haveged
十四、hdfs修改数据目录后无法启动nameNode
20260326 HDFS更改数据目录导致NameNode无法启动
十五、全组件健康图截图,纪念一下
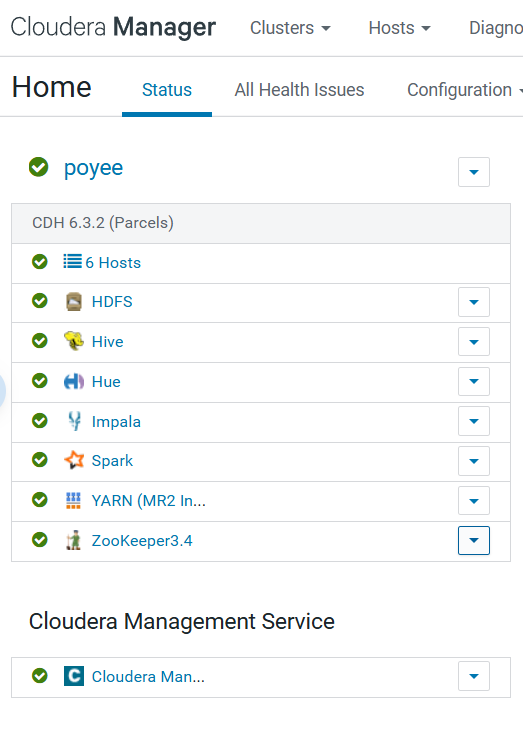
汇总: